
Data lakes began to emerge 10 years ago in response to the desire for analytic data platforms that could economically store and process large volumes of raw data. These platforms access data from multiple operational applications in a variety of formats to be queried by multiple business departments for a variety of analytic workloads.
Ventana Research’s Data Lakes Dynamics Insights research illustrates that data lakes are fulfilling that promise. More than one-half of organizations use data lakes to store data from three or more operational data sources, and more than one-quarter store data in a data lake using three or more file formats. More than two-thirds of organizations are running two or more analytics workloads on data lakes, and almost 9 in 10 expect multiple business departments and functions to benefit from data lake environments.
The research also highlights how data lake environments are evolving. Initially based primarily on Apache Hadoop, data lakes are now increasingly based on cloud object storage. Additionally, while many early data lake projects were assembled by IT departments relying on their own technological expertise with homegrown scripts and code, the use of these “do-it-yourself” environments is expected to decline rapidly. Data lakes based on open standards and open formats are expected to see the greatest growth.
Data lakes have been widely adopted in the last decade and are in production with almost two-thirds (65%) of respondents to Ventana Research’s Data Lakes Dynamics Insight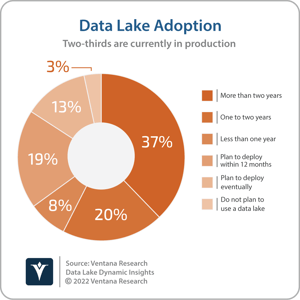 research. A further 32% plan to adopt a data lake at some point in the future. Reported benefits include better communication and knowledge sharing as well as improved competitive advantage.
research. A further 32% plan to adopt a data lake at some point in the future. Reported benefits include better communication and knowledge sharing as well as improved competitive advantage.
Data lake adopters are more confident in their ability to analyze large amounts of data. More than one-quarter (27%) of data lake adopters are very confident in their organization’s ability to analyze very large amounts of structured and unstructured data, compared to less than 1 in 10 (8%) of those that have not yet adopted a data lake. Confidence levels increase in relation to the maturity of an organization’s data lake deployment, both in terms of the number of years for which the organization has had a data lake in production, and the organization’s level of expertise.
The architecture on which the data lake is based also appears to have an impact on confidence and satisfaction. All organizations (100%) with data lakes based on open standards and open formats reported confidence in the ability to analyze very large amounts of both structured and unstructured data, compared to less than one-quarter of those using proprietary tools and cloud services. Also, almost one-half of those using open standards and open formats are satisfied with current data lake architecture compared to about one-quarter of those using proprietary tools and cloud services.
This disparity in satisfaction may be a factor in the anticipated move to open standards and open formats by almost two-fifths of those currently using data lakes based on proprietary tools and cloud services planning. Despite this shift of some data lake users from proprietary to open standards, the use of proprietary tools and cloud services is expected to grow, albeit not as fast as the use of open standards and open formats, with both fueled by adoption in organizations currently using homegrown scripts and code or those without a current data lake.
This evolution of the data lake architecture is not enough, on its own, to overcome ongoing data lake challenges, which include governance and security as well as accessing and preparing data. Almost all data lake adopters use or plan to use additional technologies to help manage and govern data lake environments, including data catalogs, open-source data management projects, custom code and scripts and data management and data governance products.
Organizations are also beginning to embrace open-source transaction management projects such as Apache Hudi, Apache Iceberg and Delta Lake. More than one-half of data lake adopters are using at least one of these emerging table formats today. The adoption of these new table formats has the potential to increase the use of data lakes as a replacement for data warehousing environments, supporting analytics workloads based on the processing of structured data. To date, less than one-quarter of organizations have adopted a data lake to replace an existing data warehouse environment, and data lake and data warehouse environments co-exist in almost three-quarters of organizations.
Variance in terminology could also have an impact on adoption of data lakes. We see some vendors and organizations referring to the combination of structured data processing.png?width=300&name=VR_2022_Analytic_Data_Platforms_Assertion_3_Square%20(1).png) functionality and cloud object storage as a data lakehouse, with the term data lake used specifically to refer to the cloud object storage layer. We assert that by 2024, more than three-quarters of current data lake adopters will be investing in data lakehouse technologies to improve the business value generated from the accumulated data. As advanced cloud data warehouse environments are also designed to take advantage of cloud object storage, we could see an increase in the number of organizations using a data lake (i.e., the cloud storage layer) as a source of information for the data warehouse, potentially alongside a data lakehouse.
functionality and cloud object storage as a data lakehouse, with the term data lake used specifically to refer to the cloud object storage layer. We assert that by 2024, more than three-quarters of current data lake adopters will be investing in data lakehouse technologies to improve the business value generated from the accumulated data. As advanced cloud data warehouse environments are also designed to take advantage of cloud object storage, we could see an increase in the number of organizations using a data lake (i.e., the cloud storage layer) as a source of information for the data warehouse, potentially alongside a data lakehouse.
The data lake is at a critical point in its evolution. It is now well-established with widespread adoption that is delivering on the original promised benefits. Data lake adopters have greater confidence in their ability to process and generate value from large and multi-faceted datasets. That initial success, combined with emerging and maturing functionality, is increasing expectations. The DIY phase of adoption is over. The use of proprietary products will continue to grow, but data lakes are shifting to open standards. Despite ongoing coexistence, the line between data warehouses and data lakes will continue to blur. Organizations that have not already done so should explore the potential benefits of data lakes, while those that have embraced proprietary or homegrown architectures should look to the potential advantages of open standards and open formats.
Ventana Research
Ventana Research, now part of Information Services Group, provides authoritative market research and coverage on the business and IT aspects of the software industry. We distribute research and insights daily through the Ventana Research community, and provide a portfolio of consulting, advisory, research and education services for enterprises, software and service providers, and investment firms. Sign up for free community membership to receive email notifications on research and insights.
